OpenWebUI 구성¶
OpenWebUI를 사용하면 백엔드에서 실행 중인 다양한 LLM 모델을 웹 채팅으로 이용할 수 있습니다
구성 목표¶
연동 가능한 백엔드 LLM¶
| 모델명 | 포트 | endpoint |
|---|---|---|
| openai/gpt-oss-120b | 8355 |
http://172.17.0.1:8355/v1 |
| openai/gpt-oss-20b | 8356 |
http://172.17.0.1:8356/v1 |
| Qwen/Qwen3-30B-A3B-Instruct | 8357 |
http://172.17.0.1:8357/v1 |
| Qwen/Qwen3-Coder-30B-A3B | 8358 |
http://172.17.0.1:8358/v1 |
| Qwen/Qwen2.5-VL-32B-Instruct | 8359 |
http://172.17.0.1:8359/v1 |
| nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16 | 8360 |
http://172.17.0.1:8360/v1 |
| mistralai/Devstral-Small-2-24B-Instruct-2512 | 8361 |
http://172.17.0.1:8361/v1 |
| qwen3-vl:32b, etc. | 11434 |
http://172.17.0.1:11434/v1 |
실행¶
1단계: Docker 이미지 다운로드¶
2단계: 실행 스크립트¶
~/lab/LLMs/start-open-webui.sh
#!/usr/bin/bash
export PORT=8080
export CONTAINER="open-webui"
docker stop $CONTAINER 2>/dev/null
docker rm $CONTAINER 2>/dev/null
docker run -d \
--name $CONTAINER \
-p $PORT:8080 \
--gpus all \
-v $PWD/open-webui-data:/app/backend/data \
-e OLLAMA_BASE_URL=http://172.17.0.1:11434 \
--restart unless-stopped \
ghcr.io/open-webui/open-webui:main
3단계: 실행 및 접속¶
브라우저에서 http://[IP]:8080 접속
연동 구성 방법¶
vLLM 모델 주의
vLLM으로 구동되는 모델(예: Qwen3-30B)은 모델 IDs를 동일하게 입력해야 합니다.
TensorRT 구동 모델은 이름을 변경해도 무방합니다.
설정 단계¶
1단계: 설정 진입
좌측 하단 프로필 아이콘 → 설정 → 관리자 설정
2단계: 연결 추가
연결 → OpenAI API → 연결 편집
| 항목 | 값 |
|---|---|
| 연결 방식 | 로컬 |
| URL | http://172.17.0.1:8355/v1 |
| 인증 | 없음 |
| 모델 IDs | gpt-oss-120b |
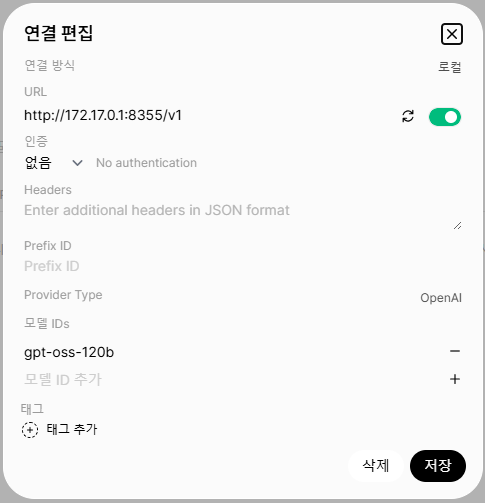
※ 참고: 컨테이너에서 호스트에 접근하기 위해 Docker Bridge IP 172.17.0.1을 사용합니다.
3단계: 추가 모델
동일한 방식으로 나머지 모델의 API Endpoint를 추가합니다.