TRT-LLM 구성¶
NVIDIA TensorRT-LLM은 대규모 언어 모델의 추론 성능을 극대화하는 고성능 추론 엔진입니다.
TensorRT-LLM이란?
- TensorRT 기반 최적화로 낮은 지연 시간과 높은 처리량 달성
- FP8, INT4/INT8 등 양자화 지원으로 메모리 사용량 및 계산 복잡도 감소
- GPT, Llama, Falcon 등 주요 LLM 아키텍처를 TensorRT 엔진으로 변환하여 실행
구성 결과¶
| 목표 | 설명 |
|---|---|
| 고성능 추론 엔진 | gpt-oss-120b 모델을 TensorRT-LLM으로 구성 |
| 사용자 인터페이스 | OpenWebUI와 연결하여 채팅 인터페이스 제공 |
| API 서비스 | OpenAI 호환 API Endpoint 제공 |
전제 조건¶
| 범주 | 항목 | 세부 내용 | 비고 |
|---|---|---|---|
| 하드웨어 | 기기 | DGX Spark GB10 | NVIDIA H/W |
| 네트워크 | 인터넷 | 연결됨 | 모델/이미지 다운로드 필수 |
| 소프트웨어 | Docker | 미리 설치됨 | 컨테이너 구동 필수 |
| 소프트웨어 | Python3, Pip | 미리 설치됨 | HuggingFace 다운로드 |
| 소프트웨어 | NVIDIA Driver | 최신 버전 | GPU/CUDA 필수 |
TRT-LLM 구성¶
1단계: 모델 다운로드¶
※ hf 명령어를 못 찾는 경우에는 ~/.local/bin/hf auth login 직접 실행
2단계: Docker 이미지 다운로드¶
3단계: 실행 스크립트 생성¶
홈 디렉토리에 trt-llm 디렉토리를 생성하고 스크립트를 생성합니다.
~/trt-llm/start-trt-llm.sh
#!/usr/bin/bash
docker stop trt-llm-server 2>/dev/null
docker rm trt-llm-server 2>/dev/null
export MODEL_HANDLE="openai/gpt-oss-120b"
docker run -d \
--name trt-llm-server \
--gpus all \
--ipc host \
-p 8355:8355 \
-e MODEL_HANDLE="$MODEL_HANDLE" \
-v $HOME/.cache/huggingface/:/root/.cache/huggingface/ \
-v ./harmony-reqs/:/tmp/harmony-reqs/ \
-v ./extra-llm-api-config.yml/:/tmp/extra-llm-api-config.yml/ \
--restart unless-stopped \
nvcr.io/nvidia/tensorrt-llm/release:spark-single-gpu-dev \
bash -c '
export TIKTOKEN_ENCODINGS_BASE="/tmp/harmony-reqs" && \
trtllm-serve "$MODEL_HANDLE" \
--max_batch_size 64 \
--trust_remote_code \
--host 0.0.0.0 \
--port 8355 \
--extra_llm_api_options /tmp/extra-llm-api-config.yml
'
4단계: 기동 및 점검¶
기동
로그 확인
API 테스트
curl -s -X POST http://localhost:8355/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-oss-120b",
"messages": [{"role": "user", "content": "안녕하세요. 모델 준비가 완료되었나요?"}],
"max_tokens": 50,
"temperature": 0.7
}' | jq
채팅 인터페이스 구성¶
OpenWebUI 실행¶
trt-llm 디렉토리에 start-open-webui.sh 파일을 생성합니다.
start-open-webui.sh
브라우저에서 http://localhost:8080 접속
TRT-LLM 연결¶
1단계: 설정 진입
좌측 하단 프로필 아이콘 → 설정 → 관리자 설정
2단계: 연결 추가
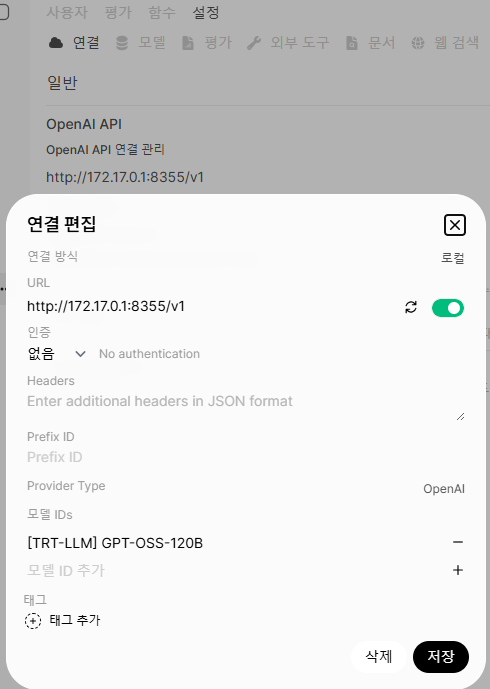
연결 → OpenAI API → 연결 편집
| 항목 | 값 |
|---|---|
| 연결 방식 | 로컬 |
| URL | http://172.17.0.1:8355/v1 |
| 인증 | 없음 |
| 모델 IDs | [TRT-LLM] GPT-OSS-120B |
3단계: 완료
설정 완료 후 채팅 화면에서 모델 선택 가능
OpenAI 호환 API Endpoint¶
TRT-LLM은 기본으로 OpenAI 호환 API Endpoint를 제공합니다.
| 접속 유형 | URL | 비고 |
|---|---|---|
| 로컬 접속 | http://localhost:8355/v1 |
DGX Spark 내부 |
| Docker 내부 | http://172.17.0.1:8355/v1 |
컨테이너에서 호스트 접근 |
| 원격 접속 | http://[IP]:8355/v1 |
다른 PC에서 접속 |